Story Points in Action
The post is focused on providing some tips and tricks which can be helpful when carrying out Story Point based estimation on an agile project.
In the following I have chosen to refer to User Stories as the elements in my Product Backlog.
Preparing estimation
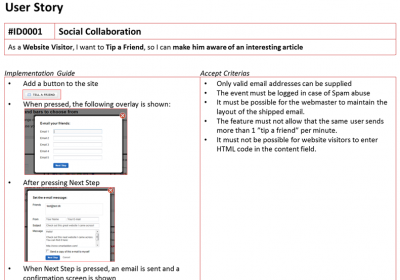
Before being able to estimate relatively, you need to define a Base Story. Here it is essential that everyone on the team can relate to the Base Story and takes ownership of it. If you work with web development projects, you might be able to get inspiration from the User Story below. My experience is at least that it works well as a Base Story based on both size and complexity.

However, as mentioned it is imperative that the team takes ownership of the base story and commits to it throughout the project. If is not willing to take ownership of the Base Story, you should invest the time and effort needed to define a Base Story the team takes ownership of.
Once you have the base story in place, you assign it 5 Story Points. That way you will be able to support both smaller and bigger User Stories in the Product Backlog. The side effect of forcing the Base Story to 5 Story Points, is that your Base Story must correspond to an average User Story in the Product Backlog.
For the team to get the right understanding of the Base Story (and other User Stories), it includes the following activities:
- Development
- Peer review
- Documentation
- Automated tests
- Writing and executing test cases
- Validation against User Story
When a basic understanding is established in the team, they should break down the Base Story into the tasks. The purpose of this task breakdown is not to carry out a detailed estimation of each task, but to ensure that the team has a common understanding of the complexity involved.
At this stage you shouldn’t be too worried about spending a long time discussing the Base Story. It is vital for the project transparency and success that you get it right.
Tip: Once the team has decided on a Base Story, it should not be changed. If you for some reason have to do so, it will reset your velocity learnings and require serious involvement of the Product Owner and maybe even external stakeholders.
The Product Backlog
The product backlog is made up of User Stories in a prioritized order. In order to prioritize, the Product Owner needs to know what it takes to implement the individual User Stories. The Product Owner will usually also have to translate the estimates into $ in order to validate the business case.
To achieve this, you estimate each User Story relative to the Base Story. This means that if the team believes it will take twice as long as “Tip a fiend” to implement some other User Story, that User Story will be assigned 10 Story Points. If it takes half as long, it is assigned 2 or 3 Story Points.
If the Product Owner doesn’t have to transform the relative estimates into $ for the first couple of Sprints, the Velocity (translation factor) can be established through experience.
If the Product Owner needs translate Story Points into $ before the first Sprint is initiated, you could choose one of two approaches:
- Have the team implement the actual Base Story and then measure the performance of the team
- Make the team estimate all the previously defined tasks and then carry out a sanity check on the estimate before passing it on to the Product Owner.
Either way you need to make the Product Owner aware that you will gradually become more precise in your Velocity and that your current translation of Story Points into hours is a “qualified guess”.
Tip: If the same team uses the same Base Story across multiple projects, you can use the velocity of the previous learnings as Velocity for the new project. It multiple teams use the same Base Story across projects, you might be able to provide a “qualified guess”, based on previous experience.
Tip: Try to avoid User Stories equivalent to or greater than 40 Story Points, since the relative value becomes too great. If the team estimates a User Story to 40 points or more, you should consider breaking the User Story into smaller ones.
The Sprint Backlog
Breakdown of tasks When breaking a User Stories into tasks at the Sprint Planning session, it is essential to make the tasks are as independent as possible. If there is too great a dependency between tasks, the burn down chart will become almost worthless, and the team will only know if they are “on track” at the end of the Sprint. If there is dependency between tasks, you should either define them better or specify them in a different way.
Sprint backlog: Task estimation I am fully aware that there are many different “religions” when it comes to estimating tasks. However, it is my opinion that tasks should also be estimated relatively, and that the measurement for the relative estimates should be the Base Story.
I base my opinion on the following observations:
- If hours are used for estimating tasks, the team won’t be able to estimate as a team, due to differences between competences and experience.
- If hours are used for estimating tasks, it is very hard to keep the teams understanding of Story Points.
- If hours are used for estimating tasks, it will be hard to validate the User Story estimate against the defined tasks. IMPORTANT: The validation between User Story and Tasks is not done to control/influence the estimate, but to spot if the understanding of the scope of the User Story has changed.
Tip: In some cases I have experience inflation of the estimates throughout the Sprint Planning session due to an ever changing understanding of the Base Story. To avoid this, you can continuously “remind” the team of the Base Story – both what the scope is, and that it’s worth 5 points.
Tip: By making everyone on the team participate in the estimation process, the team acquires ownership of the estimates, and therefore work together on achieving the goal.